
DeepSeek vs 小米 MiMo:国产大模型的路线、能力和使用场景对比
一句话结论
如果你要把模型接进真实产品,优先看 DeepSeek;如果你关心国产开源全模态模型、本地部署、长上下文和研究复现,小米 MiMo 更值得细看。
截至 2026-06-07,DeepSeek 的公开 API 已经进入 V4 Preview 阶段,主推 deepseek-v4-flash 和 deepseek-v4-pro,同时兼容 OpenAI Chat Completions 与 Anthropic API。小米 MiMo 则已经从早期轻量推理模型推进到 MiMo-V2.5,公开权重覆盖文本、图像、视频、音频理解,并且也上线了 API 平台。
这两者不是简单的“谁更强”。DeepSeek 更像成熟的通用模型服务和开发者 API;MiMo 更像小米在开源全模态、长上下文、端侧/低成本路线上的技术底座。一个更适合直接用,一个更适合研究、部署和观察路线。

先说测评边界
这篇不是跑分实测,也不调用 API。原因很简单:模型测评如果没有统一提示词、统一采样参数、统一工具环境、统一评测集,最后很容易变成“截图文学”。
所以本文采用公开资料测评,只看这些信息:
- 官方 API 文档和价格页。
- 官方新闻、技术报告、模型卡。
- Hugging Face / GitHub / ModelScope 等公开模型资产。
- 公开 benchmark 的自述,但不把不同来源数据当成绝对同场竞技。
也就是说,本文更像一份选型地图:帮你判断“该先试谁、怎么试、风险在哪”,而不是宣布某个模型赢下所有场景。

模型定位
DeepSeek 的路线很清楚:把强推理、长上下文、工具调用和 API 生态打包成一个可直接接入的模型服务。
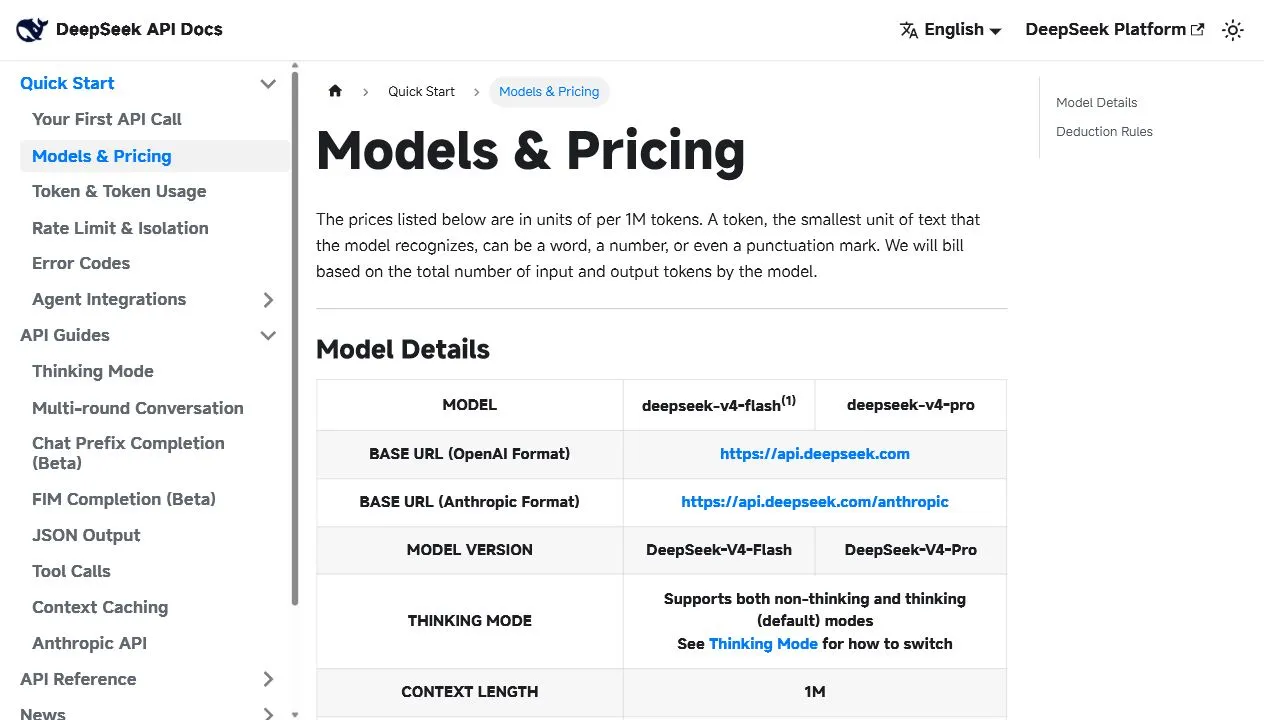
根据 DeepSeek 官方新闻,V4 Preview 提供两个主模型:DeepSeek-V4-Pro 是 1.6T 总参数、49B 激活参数;DeepSeek-V4-Flash 是 284B 总参数、13B 激活参数。官方同时强调 1M 上下文、推理/非推理双模式、Agentic Coding、数学/STEM/代码能力,以及 OpenAI / Anthropic API 兼容。
MiMo 的定位更偏“开源全模态研究基座”。MiMo-V2.5 模型卡写得很明确:它是 native omnimodal model,支持文本、图像、视频和音频理解;采用 Sparse MoE 架构,MiMo-V2.5 为 310B 总参数、15B 激活参数,MiMo-V2.5-Pro 为 1.02T 总参数、42B 激活参数,并支持最高 1M tokens 上下文。
简单拆开看:
| 维度 | DeepSeek | 小米 MiMo |
|---|---|---|
| 当前重点 | V4 API、强推理、Agent、长上下文 | MiMo-V2.5 全模态、开源权重、长上下文 |
| 产品形态 | API 服务 + Chat 产品 + 开源权重 | Hugging Face / ModelScope 权重 + API 平台 |
| 主力优势 | 易接入、生态成熟、代码/推理/工具链清晰 | 多模态开放、模型结构透明、部署实验空间大 |
| 更像什么 | 可投入产品的模型服务 | 可研究、可部署、可二次实验的模型底座 |
如果你问“哪个更适合今天拿来干活”,DeepSeek 答案更直接。如果你问“哪个更值得看技术路线”,MiMo 的开源全模态路线很有观察价值。
能力对比
先放一个不那么刺激、但更靠谱的判断:DeepSeek 和 MiMo 的 benchmark 不能简单横向硬比。
DeepSeek 的公开叙事集中在推理、代码、Agent、长上下文和 API 性价比;MiMo-V2.5 的公开模型卡则同时覆盖多模态、代码与 Agent、长上下文,并给出了模型结构、训练流程、部署方法。两边评测集、模型版本、推理设置、是否使用工具、是否启用思考模式,都可能不同。
更适合的对比方式是按使用场景看:
| 场景 | 更推荐 | 原因 |
|---|---|---|
| 通用问答 / 文案 / 总结 | DeepSeek | API 接入成熟,模型服务稳定性和使用门槛更友好 |
| 代码辅助 / Agent 编程 | DeepSeek 优先,MiMo 可试 | DeepSeek 官方明确强调 Agentic Coding;MiMo-V2.5 也强化 Agent 能力,但生态仍需验证 |
| 数学 / STEM / 推理 | DeepSeek 优先 | DeepSeek 的 R1/V4 路线长期围绕推理展开,API 直接可用 |
| 图像 / 视频 / 音频理解 | MiMo | MiMo-V2.5 是全模态模型,模型卡明确覆盖 image、video、audio understanding |
| 长上下文 | 两者都可试 | DeepSeek V4 与 MiMo-V2.5 都标注 1M 上下文,真实效果要按任务压测 |
| 本地部署 / 权重研究 | MiMo 更顺手 | MiMo 模型卡提供 SGLang、vLLM 部署说明,且 License 标注 MIT |
| 生产 API 集成 | DeepSeek 更稳 | DeepSeek API 文档、价格、兼容格式和开发者集成路径更成熟 |
这里有一个很实用的分界:你要处理的是“语言任务”,还是“全模态任务”。如果主要是文本、代码、推理和工具调用,DeepSeek 更像默认选项;如果任务里天然有图像、视频、音频理解,MiMo-V2.5 的技术路线更贴近需求。
API 与产品化
DeepSeek 的 API 体验更像一个已经成型的模型平台。官方价格页列出了 deepseek-v4-flash 和 deepseek-v4-pro,Base URL 保持 https://api.deepseek.com,同时提供 Anthropic 格式入口。两个模型都支持 1M context,最高输出 384K,并支持 JSON Output、Tool Calls、Chat Prefix Completion、FIM Completion 等能力。
截至 2026-06-07,DeepSeek 价格页显示:
| 模型 | 缓存命中输入 | 缓存未命中输入 | 输出 |
|---|---|---|---|
deepseek-v4-flash | $0.0028 / 1M tokens | $0.14 / 1M tokens | $0.28 / 1M tokens |
deepseek-v4-pro | $0.003625 / 1M tokens | $0.435 / 1M tokens | $0.87 / 1M tokens |
官方还说明,旧模型名 deepseek-chat 和 deepseek-reasoner 将在 2026-07-24 15:59 UTC 后退役;当前它们分别路由到 deepseek-v4-flash 的非思考模式和思考模式。这对开发者很关键:如果你现在还写死旧模型名,后续要提前迁移。
MiMo 这边也不再只是“放权重”。小米 MiMo API 平台的定价页显示,MiMo-V2.5 系列已开启公测,支持 OpenAI API、Anthropic API、函数调用、结构化输出、联网搜索、多模态理解、图片理解、音频理解、视频理解等入口。
截至 2026-06-07,MiMo 平台海外定价显示:
| 模型 | 输入 ≤ 256K 缓存命中 | 输入 ≤ 256K 缓存未命中 | 输出 |
|---|---|---|---|
mimo-v2.5-pro / mimo-v2-pro | $0.20 / 1M tokens | $1.00 / 1M tokens | $3.00 / 1M tokens |
mimo-v2.5 | $0.08 / 1M tokens | $0.40 / 1M tokens | $2.00 / 1M tokens |
mimo-v2-flash | $0.01 / 1M tokens | $0.10 / 1M tokens | $0.30 / 1M tokens |
如果只看 flash 档位,MiMo 的海外价格也很有竞争力;但 DeepSeek 的优势在于 API 文档、社区接入、开发者心智和文本推理生态更成熟。MiMo API 平台很值得关注,但对生产系统来说还需要自己验证稳定性、限速、区域可用性和模型输出一致性。
开源与部署
开源角度,MiMo 的可玩性更强。
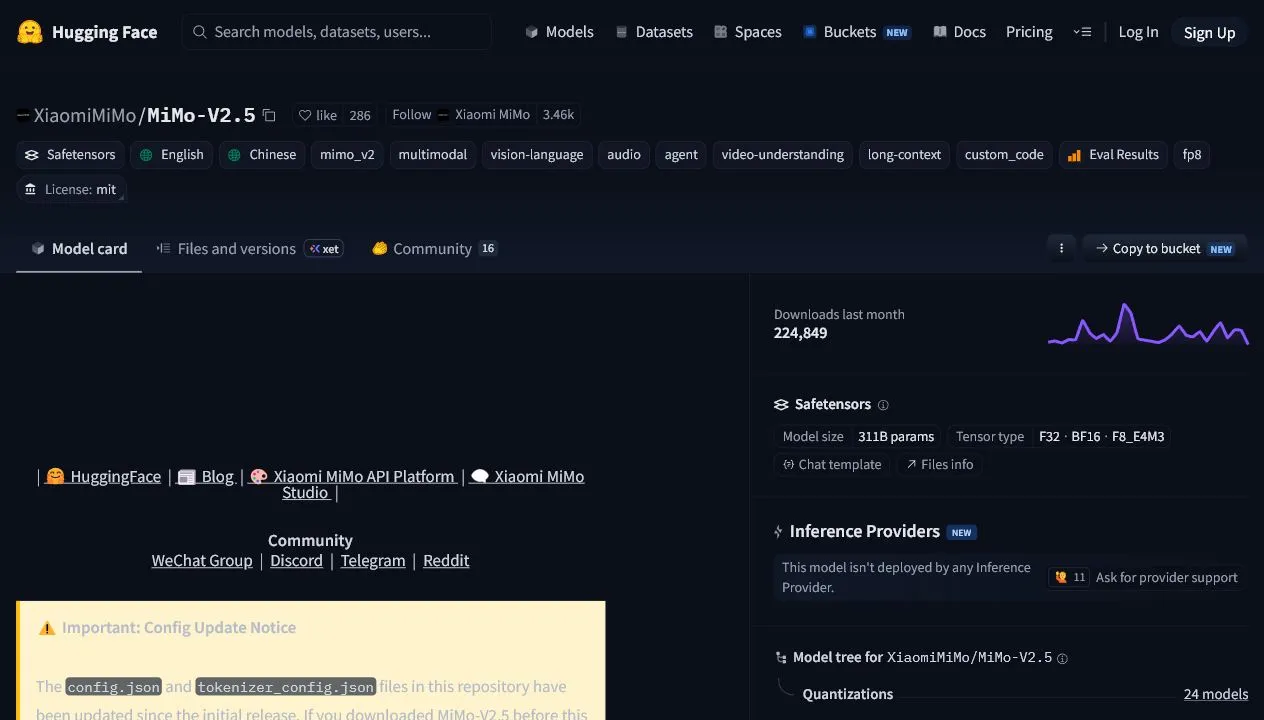
MiMo-V2.5 的 Hugging Face 页面标注 License 为 MIT,并提供 MiMo-V2.5-Base、MiMo-V2.5 等下载入口。模型卡还写明了 SGLang 和 vLLM 部署路径。对研究者、模型工程师、私有化部署团队来说,这些信息很重要:你不是只能调用黑盒 API,而是可以研究结构、部署权重、做量化和适配。
DeepSeek 也有开源权重。V4 Preview 官方新闻明确写到 “open-sourced” 并给出 Hugging Face collection。区别在于,DeepSeek 对普通开发者最强的入口仍然是 API;MiMo 则更容易让人联想到“我要把模型拿下来看看”。
本地部署时,真正决定成本的不是“模型免费”,而是这些变量:
- 激活参数规模:决定推理显存和吞吐压力。
- 上下文长度:1M tokens 很诱人,但 KV cache 和延迟会真实存在。
- 部署框架:SGLang、vLLM、量化方案、张量并行都会影响门槛。
- 多模态输入:图像、音频、视频会引入额外编码器和预处理链路。
- 运维能力:模型服务监控、批处理、缓存、限流、容错都要自己扛。
所以不要把“开源”理解成“零成本”。开源降低的是控制权门槛,不一定降低总拥有成本。尤其是 300B 以上 MoE 模型,本地跑起来和跑得好,是两件事。
成本与性能怎么理解
只看价格表,很容易得出一个过度简化结论:哪个便宜用哪个。实际没这么简单。
API 成本至少由四件事组成:输入价格、输出价格、缓存命中率、任务成功率。比如长上下文任务里,缓存命中输入价格会明显影响总成本;Agent 任务里,模型如果少走两轮工具调用,哪怕单 token 更贵,也可能总成本更低。
DeepSeek 的 V4-Flash 在公开价格里非常激进,尤其是缓存命中输入价格很低。它适合大量文本、代码、推理、总结、检索增强生成这类任务。V4-Pro 更贵,但如果任务更难、失败重试更少,也可能更划算。
MiMo 的 mimo-v2-flash 价格同样低,mimo-v2.5 和 mimo-v2.5-pro 则更偏全模态和高能力场景。它的价值不只在 token 价格,而在“同一模型路线覆盖文本、图像、视频、音频理解”。如果你的业务输入天然多模态,MiMo 可能省掉多个模型拼接的复杂度。
一句话:
文本/代码/推理主线:优先测 DeepSeek V4-Flash / V4-Pro
多模态理解主线:优先测 MiMo-V2.5 / MiMo-V2.5-Pro
极限成本任务:两边 flash 档都要实测,不要只看单价生态成熟度
DeepSeek 的优势是“开发者已经知道怎么用”。很多客户端、Agent 框架、编辑器插件、中转服务、工作流工具,都已经把 DeepSeek 当作标准模型供应商之一。它支持 OpenAI 兼容格式,也支持 Anthropic API,这让迁移成本更低。
MiMo 的生态还在成长,但它有两个很强的信号:第一,小米把 MiMo-V2.5 做成了 Hugging Face / ModelScope 可下载的公开模型;第二,MiMo API 平台已经覆盖 OpenAI / Anthropic API、AI 工具配置、多模态和 TTS 等入口。它不是只有论文和权重,而是在往平台化方向走。
不过生态成熟度不是发布页能完全证明的。真正要看的是:
- 第三方 SDK 和客户端是否稳定适配。
- 社区有没有足够多部署经验、量化方案和踩坑记录。
- 出错时能不能快速定位是模型、网关、限速、上下文还是工具调用问题。
- 生产问题有没有清晰的状态页、工单和 SLA 机制。
从这个角度看,DeepSeek 更像“现在可用的生产选项”,MiMo 更像“快速成熟中的技术选项”。
适合谁?
DeepSeek 更适合:
- 需要稳定 API 接入的产品团队。
- 做通用问答、代码助手、RAG、文档总结、Agent 工作流的开发者。
- 希望用 OpenAI / Anthropic 兼容接口快速替换模型的团队。
- 对推理、代码、长上下文有要求,但不想自己部署大模型的人。
MiMo 更适合:
- 关注国产开源多模态模型的研究者和工程团队。
- 想研究 Sparse MoE、长上下文、多模态编码器、MTP 推理加速的人。
- 需要图像、视频、音频理解,而不是只做文本生成的应用。
- 有本地部署、私有化、量化、框架适配需求的模型工程师。
如果你是独立开发者,要做一个 AI 功能,建议先用 DeepSeek 起步。如果你是模型工程团队,想研究全模态模型的结构和部署,MiMo-V2.5 更值得开仓细看。
不适合谁?
两者都不应该被无脑塞进高风险生产系统。
以下场景需要额外谨慎:
- 强合规数据:医疗、金融、政企、未成年人数据等,需要合同、审计和数据处理协议。
- 强 SLA 场景:客服、交易、监控、自动化运维等,必须压测延迟、错误率和降级策略。
- 高自治 Agent:让模型直接执行外部操作时,需要权限边界、审计和人工确认。
- 严格可复现任务:模型版本、采样参数、工具链变化都会影响输出。
- 超长上下文任务:1M context 不代表塞进去就一定能稳定找回、推理和输出。
模型越强,越容易让人低估系统工程。真正上线时,提示词、缓存、重试、观测、权限、审计、成本上限,比模型名更决定体验。
我的选型建议
如果只能给一个默认建议:先用 DeepSeek 做产品原型,再用 MiMo 做多模态和开源部署验证。
更具体一点:
| 目标 | 建议 |
|---|---|
| 快速上线文本 AI 功能 | DeepSeek V4-Flash 起步,难任务再试 V4-Pro |
| 代码 Agent / 自动化开发 | DeepSeek 优先,关注工具调用与上下文成本 |
| 多模态理解 | MiMo-V2.5 优先测试,尤其是图像/视频/音频输入 |
| 本地部署研究 | MiMo-V2.5 / Base 权重优先,按 vLLM/SGLang 路线验证 |
| 极低成本批处理 | 两边 flash 档小样本压测,看成功率而不是只看单价 |
| 长上下文任务 | 必须自建测试集,验证检索、推理、输出稳定性 |
不要把模型选型做成信仰题。更健康的做法是准备 20–50 条自己的真实任务,固定提示词、参数和判分标准,然后同时跑 DeepSeek 和 MiMo。你会很快发现:真正的胜负常常不在排行榜,而在你的业务输入里。
总结
DeepSeek 和小米 MiMo 代表的是两条不同路线。
DeepSeek 更完整、更产品化、更适合开发者直接接入。它的优势是 API、推理、代码、Agent、长上下文和生态成熟度。对大多数想“今天就把 AI 功能做出来”的团队来说,DeepSeek 是更稳的起点。
MiMo 更像一个值得长期观察的国产开源全模态路线。MiMo-V2.5 把文本、图像、视频、音频理解、长上下文、MoE、开源权重和 API 平台放到一起,技术野心很明显。它现在最适合研究、部署实验、多模态应用验证,以及想掌握模型控制权的团队。
最后的判断很朴素:
要省心接入:DeepSeek
要开源研究:MiMo
要多模态理解:MiMo
要文本/代码/推理产品化:DeepSeek
要真正上线:都要用自己的任务集压测模型选择不是押宝,是工程决策。别问“谁赢了”,先问“我的任务是什么、约束是什么、失败成本是什么”。这样选出来的模型,才不会只是看起来很强。